Lamia Benamara and Clémence Magnien
Proceedings of the third International Workshop on Network Science for Communication Networks (NetSciCom 2010), In conjunction with IEEE Infocom 2010.
In many systems, such as P2P systems, the dynamicity of participating elements, or churn, has a strong impact. As a consequence, many efforts have been made to characterize it, and in particular to capture the session length distribution. However in most cases, estimating it rigorously is difficult. One of the reasons is that, because the observation window is by definition finite, parts of the sessions
that begin before the window and/or end after it are missed. This induces a bias. Although it tends to decrease when the observation window length increases, it is difficult to quantify its importance, or how fast it decreases.
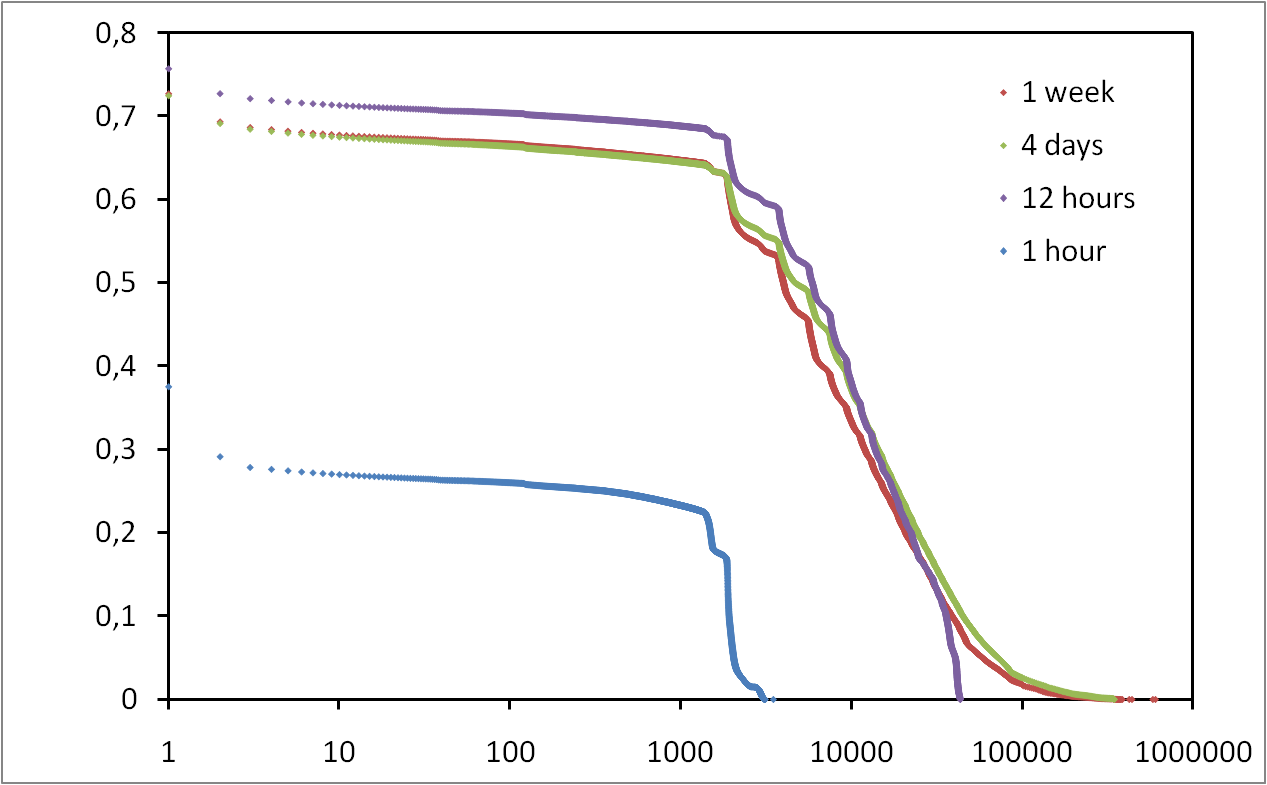
Here, we introduce a general methodology that allows us to know if the observation window is long enough to characterize a given property. This methodology is not specific to one study case and may be applied to any property in a dynamic system. We apply this methodology to the study of session lengths in a massive measurement of P2P activity in the eDonkey system. We show that the measurement needs to last for at least one week in order to obtain representative results. We also show that our methodology allows us to precisely characterize the shape of the session length distribution.
Download